Understanding Normal Distribution
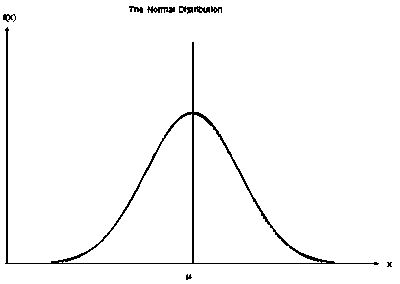
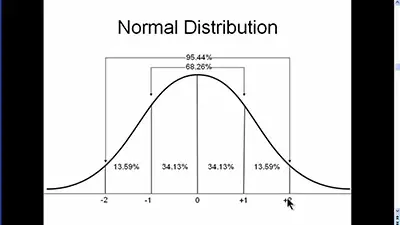
One of the first things that you learn when you start studying statistics is the normal distribution which is also known as the Gaussian distribution or normal bell curve. Discover the z tables you need here. As you can see from the image above, the normal distribution tapers out in both tails and is dense … Read more